
# fullstack/database/p240610/select_group_function.sql
[그룹 함수] 집계 함수
count(컬럼명) : 로우 개수 - null 제외
count(*) : 로우 개수 - null 포함
sum(컬럼명) : 합
avg(컬럼명) : 평균
max(컬럼명) : 최대값
min(컬럼명) : 최솟값
[문법] 위치 다르게 하면 Syntax Error
select 컬럼명 1, 그룹함수(컬럼명 2) from 테이블명 // 여기까지 필수
where 조건 // row 와 관련
group by 컬럼명 2
having 조건
[문제 1] 총 사원(직원) 수
select count(emp_no) from employees; # emp_no 의 개수 반환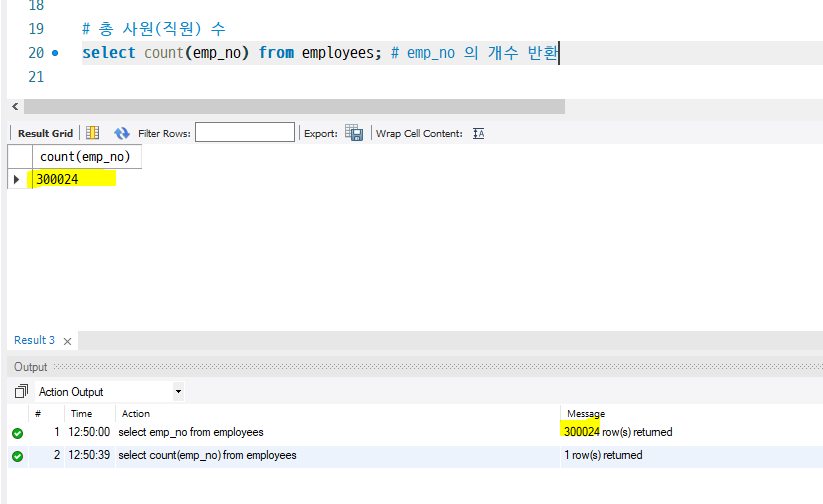
select count(emp_no), count(*) from employees; # emp_no 칼럼은 기본키로, 기본키는 null 이 올 수 없어서 개수 같음
null 값을 허용한 칼럼에서 확인 해보기 !
select * from titles limit 5;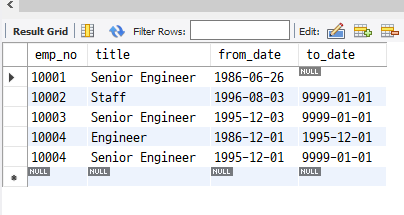
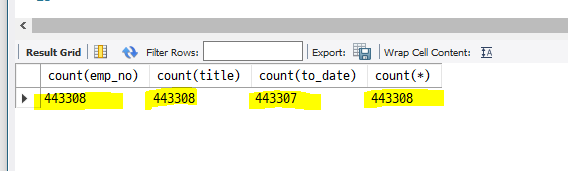
select count(emp_no), count(title), count(to_date), count(*) from titles; # null(알 수 없는 값) 값 제외
칼럼을 기준으로 칼럼이 갖고 있는 값으로 count !
하지만 칼럼에 null, 알 수 없는 값이 온다면 개수에 제외하구 count 해줌
count(*) 는 칼럼명이 없기 때문에 from 테이블 전체를 보기 때문에 null 값이 있어도 포함해서 count 해줌
[문제 2] 직원들 연봉 전체 합, 최고 연봉, 최저 연봉
select sum(salary) as '연봉 전체 합', max(salary) as '최고 연봉', min(salary) as '최저 연봉' from salaries;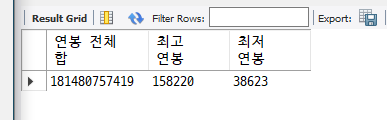
[문제 3] 직원의 성별 수
select gender, count(emp_no) from employees
group by gender;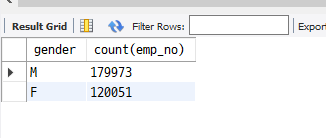

[문제 4] 직책별 직원 수
select title as '직책', count(emp_no) as '직원 수'
from titles
group by title;
select title as '직책', count(*) as '직원 수'
from titles
group by title;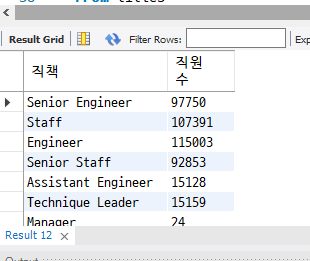
[문제 5] 2만 이상인 직원수를 갖는고 s로 시작하는 직책 조회
# [방법 1] 굳이 집계, 그룹하지 않아도 됨
select title as '직책', count(*) as '직원 수'
from titles
where title like 's%'
group by title
having count(*) >= 20000;
# [방법 2] (가공된)그룹화 값으로 having
# 이미 집계 후 그룹화 후 조건을 주는 것과 다름 이 방법이 더 나은 선택인듯
# 쿼리 실행 속도가 빠름
select title as '직책', count(*) as '직원 수'
from titles
group by title
having count(*) >= 20000 and title like 's%';
[문제 6] d001, d002, d009 각 부서의 인원 수 조회
select dept_no as '부서명', count(emp_no) as '인원수'
from dept_emp
group by dept_no
having dept_no like 'd001' or dept_no like 'd002' or dept_no like 'd009';
근데 중복된다 ! 이럴 때 in 연산자 사용
select dept_no as '부서명', count(emp_no) as '인원수'
from dept_emp
group by dept_no
having dept_no in ('d001', 'd002', 'd009');
근데 where 절로 해두 되지 않남 ?
select *
from dept_emp
where dept_no in ('d001', 'd002', 'd009')
group by dept_no;
에러 난다 !
| 0 | 1 | 15:58:22 | select * from dept_emp where dept_no in ('d001', 'd002', 'd009') group by dept_no | Error Code: 1055. Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'employees.dept_emp.emp_no' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by | 0.000 sec |
그럼 이렇게 하면 ?
select dept_no
from dept_emp
where dept_no in ('d001', 'd002', 'd009')
group by dept_no;
이건 또 에러가 아님 !
그 이유는 그룹화를 하게 되면 집계 함수를 사용하게 되는데
그룹을 사용하는 기준(dept_no)을 select(dept_no) 로 하게 되면 집계된 게 안된 것 !
'Others > 데이터베이스' 카테고리의 다른 글
| [SQL] VIEW 문법 정리 및 예제 (0) | 2024.06.18 |
|---|---|
| DB 구축 단계 (0) | 2024.06.17 |
| [SQL] SubQuery : 서브 쿼리 문법 정리 및 예제 (0) | 2024.06.16 |
| [SQL] JOIN 문법 정리 및 예제 (0) | 2024.06.16 |
| [SQL] 데이터형 (0) | 2024.06.16 |